前言
更新日志
2021/12/15:
虽然说还有N个项目没有写完,考试也迫在眉睫,但是我啊依旧不慌,还是学技术最令人心情愉悦了!当然,话是这么说,后面该复习还是得复习啊,哦——是预习。总之在学习考试科目的同时,我也会抽空持续学习技术的!
2021/12/16
明天还要做数据库的上机实验,但是我还是选择通宵了,没错,现在是凌晨四点,说实话感觉有点累,但是还是再学会儿吧,四点半就回寝室…
2021/12/17
爆肝三日终于Node入门,学到FS文件操作的时候当时我就意识到了,或许项目中前后端传递图片的技术已经近在眼前!真的太强了,伟哉JS!2022/02/07
补充关于AMD和CMD的少量知识点2022/02/25
补充Node常用模块及其API2022/05/06
考试终于是告一段落了
更新async和net模块部分
多余的话
Node.JS真是了不起啊,想想就觉得刺激!
这里只是皮毛,学完了最多算是入门的入门~~
基础知识
终端
小黑窗、命令行窗口、命令提示符、DOS窗口、shell、CMD窗口、终端说的都是一个东西啊…
这个东西过于基础,放在这里只是为了让大家知道要学这个,此处就不再赘述
环境变量
格式是键值对。
以path变量为例,其值是多个路径,路径间以分号隔开
这些路径,能够在任意目录下访问
比如配置一个D:/hello
这里的hello是一个txt文件
我们在终端里执行如下内容:
C:\User>hello.txt
系统会先到User目录下寻找hello.txt,如果没找到,那么就会去环境变量path中寻找,这样就访问到了hello.txt
环境变量可以分为两类
用户变量
当前用户能够使用
系统变量
这台计算机上的所有用户都能够使用
进程和线程
概念不再赘述,详见操作系统笔记
简单提下为什么浏览器主进程(渲染进程)是单线程
如果原生变为多线程,那么渲染页面和JS解析同时进行,
由于并发和异步可能会导致最终页面出现和预期不符的结果
Node.JS基础
概念
Node.JS还没有诞生的时候,JS顶天就是操作浏览器.
Node.JS是一个能够在服务器端运行JavaScript的开源跨平台JavaScript运行环境。
Node采用Google开发额度V8引擎运行JS代码,使用事件驱动、非阻塞、异步I/O等技术提高性能。
Node大部分内容都用JS编写。
但是Node.JS诞生了,JS能够撼动整个计算机的世界.
性能提升的原理
浏览器作为客户端,和服务端交互存在两个过程:请求和响应。而服务端和数据库之间存在I/O操作。
客户端对于硬件层面的I/O操作就是无能为力,但是可以优化请求和响应相关的逻辑代码可以提升程序的性能。
客户端(此处指传统浏览器)每发出一个请求,客户端都会为之创建一个线程,而在其I/O完成之前,该线程会一直等待,即阻塞
当有大量请求时,会出现大量请求阻塞,内存资源会被极大的消耗
Node.JS的解决方案就是Node模式
避免一个线程忙等待,当请求执行到I/O操作时,该线程不会阻塞而是选择去服务其他请求,从而避免了大量线程白白浪费资源。
当然,要注意Node服务器单线程,意思是只有一个线程忙活,所以它需要超高速地服务不同的请求。
如果有做多线程的需求,可以考虑分布式,但这个概念不在话下。
为什么是JavaScript
有如此多的语言,但是为什么Ryan Dahl选择在JavaScript的基础上进行改动,这是因为C/C++,Java等传统服务端语言的模式已经根深蒂固,
想要进行大刀阔斧的改革变得尤其困难,而JavaScript在这方面还像是一片从未开发的沃土,而且正值Google推出V8引擎,这使得JavaScript变成了最好的选择。
也正是从此开始,JavaScript从一个需要浏览器支撑的脚本语言变成了独立自主的面向对象语言,也就是说,JavaScript从此站了起来!
应用实例
Node.JS虽然能够做服务端,但是大数据的能力依旧不如Java。
淘宝的后台服务器采用Java服务器,但是会在客户端和后台服务器之间加一层Node.JS服务器,因为Node.JS解析渲染页面的能力要更强一些,
这样的结构可以加速页面的解析和渲染。
Node.JS发展史
| 时间 | 事件 |
|---|---|
| 2009 | 瑞安·达尔发布Node.JS的最初版本 |
| 2011 | npm诞生 Node.JS发布Windows版本 Node超越Ruby on Rails(一个Web框架) |
| 2012 | 瑞安·达尔离开Node项目 |
| 2014 | Node的分支IO.JS诞生 |
| 2015 | Node.JS基金会成立 Node.JS合并IO.JS成为Node 4.0(合并后凭空出现的版本号) |
| 2016 | Node 6.0发布 |
| 2017 | Node 8.0发布 |
| 2021 | 某佑开始学习Node.JS |
朝着前辈们的背影,踏上这伟大的道路!!!
简单使用Node.JS
终端运行Node.JS
win + r打开命令提示符终端,输入node后回车开启,此后便可以开始输入JS代码
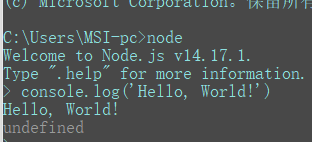
输入.exit或ctrl + c两次后退出
当然,这样写十分不方便,所以我们还可以使用下面这种形式来用node执行JS代码


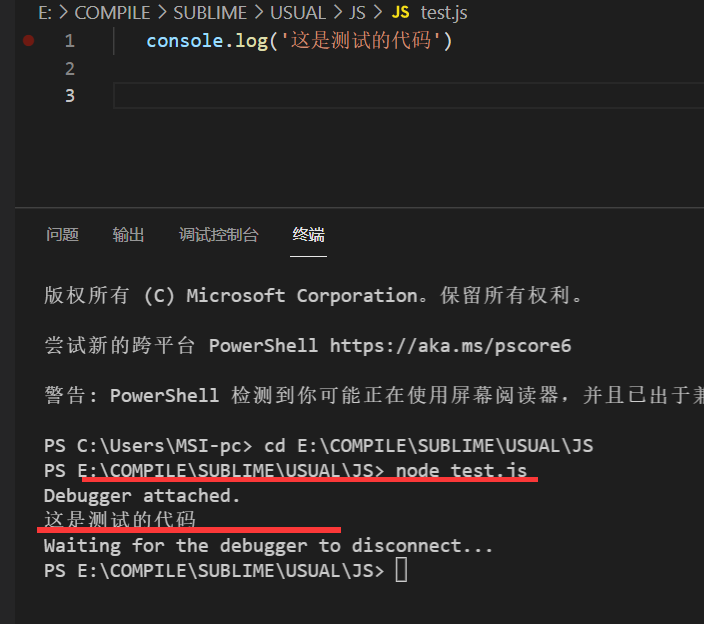
集成环境运行Node.JS
当然,也可以在webstorm或者vscode提供的终端执行以上操作
COMMONJS规范
啊不是吧,这几天才知道TypeScript还有几个稀奇古怪的Script,这里又来个COMMONJS…
注意,现在已经采用ES6标准了,但COMMONJS还是要会
概念
ECMAScript5的缺陷
COMMONJS提出时,还没有ES6,所以下述内容是针对ES5的
1.没有模块系统(ES6有了,现在可以忽略这一条)
2.标准库较少
3.没有标准接口
4.缺乏管理系统
COMMONJS的提出
最开始是用于服务端的标准而不是浏览器环境
这个规范希望JS能够在任何地方运行
它也提出了JS模块化早期的一些内容,这些内容在Node中有较为广泛的应用
1.模块引用
通过require()来引用模块,参数是一个路径,返回值是引入的对象
这里需要注意,当参数为相对路径时,必须以.或者..开头
2.模块定义
在Node中,一个JS文件就是一个模块,并且每一个JS文件中的代码都是独立运行在一个函数中的,所以一个模块中的变量和函数在其他模块中无法访问(除非exports)
3.模块标识
通过exports.v这种形式来暴露内容,exports相当于该模块暴露出去的部分
能够通过模块标识找到该模块,具体模块标识参见下述内容
模块分为两个大类:
核心模块
由node引擎提供的模块,其标识是模块的名字
(意味着不需要使用相对路径,直接把模块名字作为require的参数即可)
文件模块
由用户自己创建的模块,其标识是文件的路径
示例
建立这样一个目录结构
暴露test2中的内容
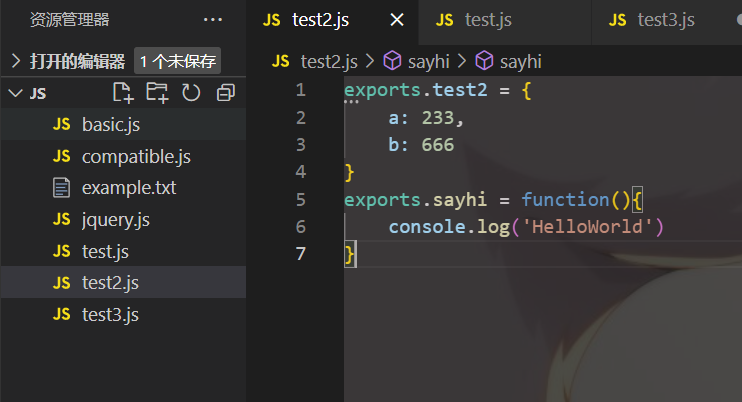
test引入
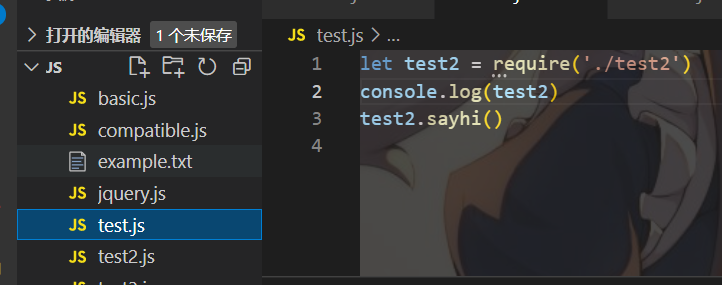
运行结果

AMD
在COMMONJS之后呢,还出现了一种叫做AMD(Asynchronous Module Definition,异步模块定义)的规范,形如:
define('getSum', ['math'], function (math) {
return function (a, b) {
console.log('sum: ' + math.sum(a, b))
}
})
define(function(){
var exports = {};
exports.method = function(){...};
return exports;
})它只有一个接口,那就是define,把要模块化的内容包起来,Node就可以看做是做了隐式的define包装
RequireJS就是实现了AMD的著名例子(注意AMD只是规范,Require.JS是其实现)
CMD
提到了AMD就顺带一提CMD,CMD很多地方和AMD类似
define(function(require,exports,module){...})而Sea.JS就是实现了CMD的著名例子
模块的函数本质
global全局对象
a = 5
// 记住这种声明是直接变成全局变量
// 全局变量保存在global中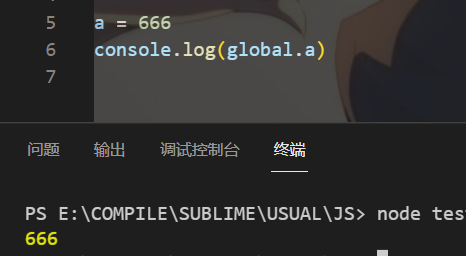
证明模块的函数本质
上面的内容有提到过,模块内的变量和函数相当于是放到一个函数中的,那么如何证明呢?
答案是函数特有的伪数组对象arguments
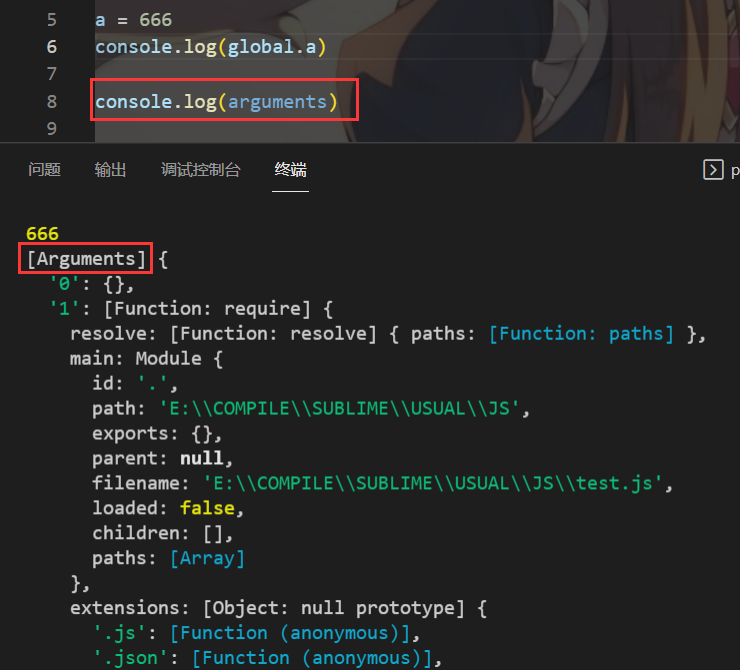
那么我们能不能瞅瞅这个函数呢?
当然可以,arguments里有一个叫callee的方法,查看当前执行的函数对象
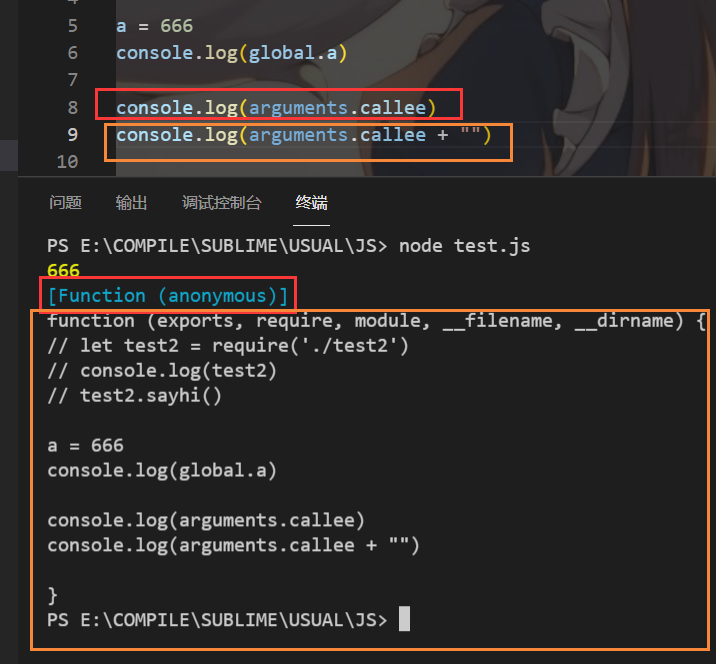
橙色的部分是通过字符串拼接,让对象调用了toString方法变成字符串达到展开的效果,也就是说效果和下面这段代码等价
console.log(arguments.callee.toString())总结一下就是,模块会把内容(包括注释)装进一个这样的函数里面
function (exports, require, module, __filename, __dirname) {
//这是模块的内容
}所以除了隐式声明之外,模块中写的内容都是局部的。
五个参数
通过观察参数,我们发现exports,require是通过参数传递进来的,而剩下三个参数则是
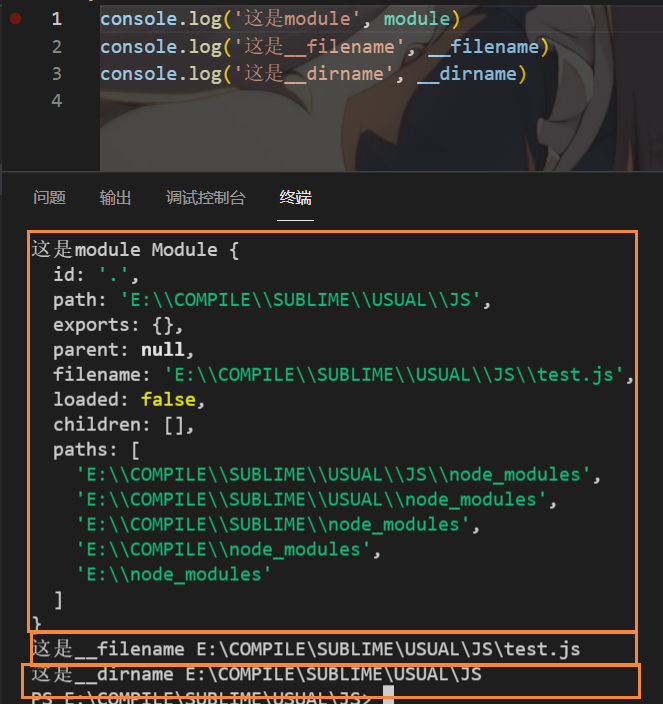
总结就是
| 名称 | 介绍 |
|---|---|
| exports | 用来将变量或函数暴露到外部的对象 |
| requires | 用来引入外部模块的函数 |
| module | 代表当前模块本身的对象,exports是其属性 |
| __filename | 当前模块的完整路径 |
| __dirname | 当前模块所在的目录文件的完整路径 |
上面提到了,exports是module的一个属性,那么我们就要讨论一下module.exports和直接exports
比较两种导出方式
首先复习一下栈内存和堆内存
栈内存
以键值对的形式存放变量名和变量值
堆内存
存放引用数据类型的内容,比如对象的内容和对象的地址
(栈内存中存放对象名和对象的地址)
那么,以下代码的执行结果是?
let obj = new Object()
let obj2 = obj
obj.name = '帅'
obj2.name = '俊'
console.log(obj.name, obj2.name)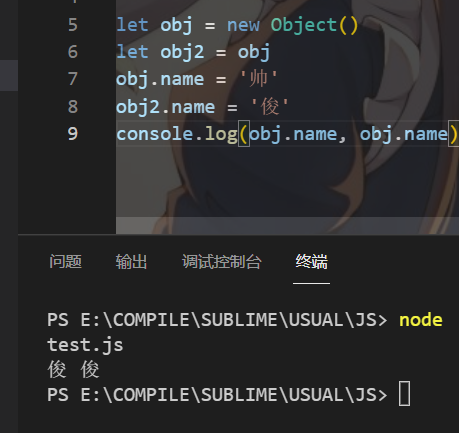
let obj = new Object()
let obj2 = obj
obj.name = '帅'
obj2.name = '俊'
obj2 = null
console.log(obj, obj2)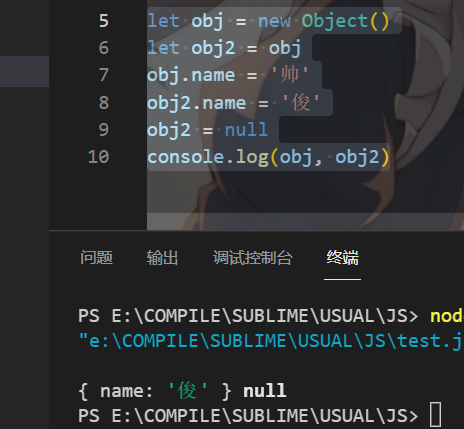
总结就是修改obj.name是修改的对象,修改obj只是修改指向
那么同样的,对于exports和module.exports也是一样
首先在test3.js里写下如下代码:
exports.a = '试图导出一条信息a'
module.exports = {
b: 'module.exports修改的是导出对象本身'
}
exports = {
c: '直接exports修改的是exports的指向'
}
在test.js中则写下如下代码:
let test3 = require('./test3.js')
console.log(test3)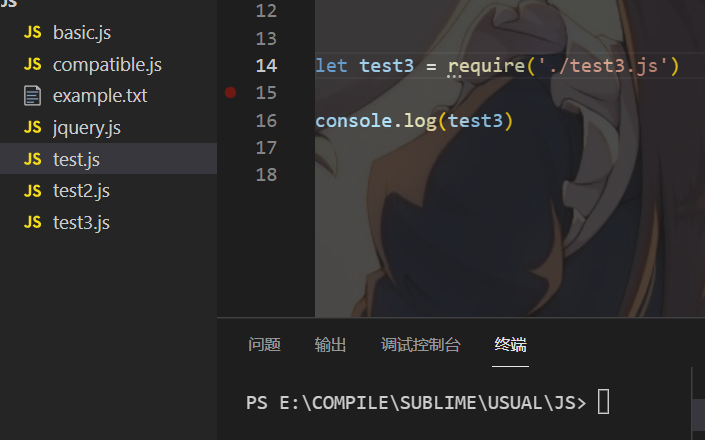
我们先来分析一下,
之前我们可以通过exports.v这种形式添加暴露的内容,是因为exports指向了module.exports,require返回的是module.exports,所以我们的结果是
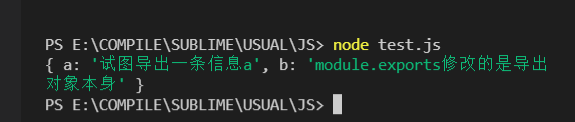
但是如果我们把test3.js中的代码顺序调整为
module.exports.b = 'module.exports修改的是导出对象本身'
exports = {
c: '直接exports修改的是exports的指向'
}
exports.a = '试图导出一条信息a'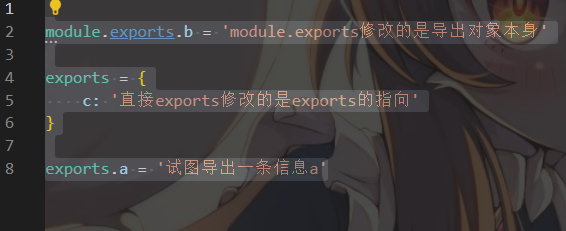
运行结果则是
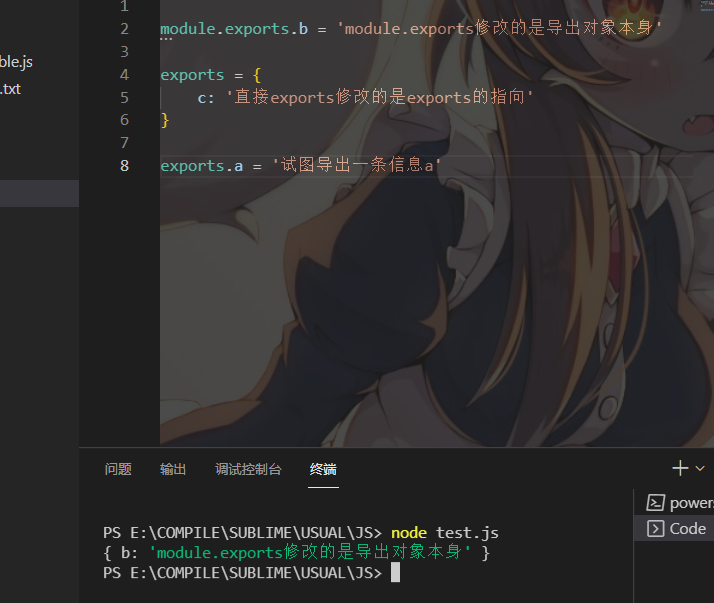
所以建议都使用对象调用内部成员的方式来暴露信息
包
概念
COMMONJS的包规范由包结构和包描述文件两个部分组成
包结构
用于组织包中的各种文件
包描述文件
描述包的相关信息,以供外部读取分析
包规范允许我们将一组先关的模块组合到一起,形成一组完整的工具
包结构
包实际上就是一个压缩文件,解压后应该还原为目录。
一个标准的目录应该包含如下文件:
1.package.json 描述文件(必有)
2.bin 可执行二进制文件
3.lib js代码
4.doc 文档
5.test 单元测试
包描述文件
包描述文件用于表达非代码相关的信息,
它是一个JSON文件,也就是package.json,这是包的标志。
位于包的根目录下,是包的重要的组成部分。
举个例子,打开一个vue项目就能发现package.json

其中,会发现版本号前面可能有~或者^符号,这是版本号的语义化(虽然我没看出来哪里语义化)
~代表强调小版本,指的是形如x.y.z的版本号上的z这一位,更新时会尽可能增大z来更新
^同理,代表中版本,指的是y这一位,
NPM
概念
Node Package Manager,Node包管理工具,
COMMONJS包规范是理论,NPM是一种实践,
对于Node而言,NPM帮助其完成了第三方模块的发布、安装和依赖等。
借助NPM,Node与第三方模块之间形成了很好的一个生态系统
由于经常使用NPM,所以这部分稍微讲其他生疏一些的内容
初始化包
执行下面这行shell指令开启初始化流程
npm init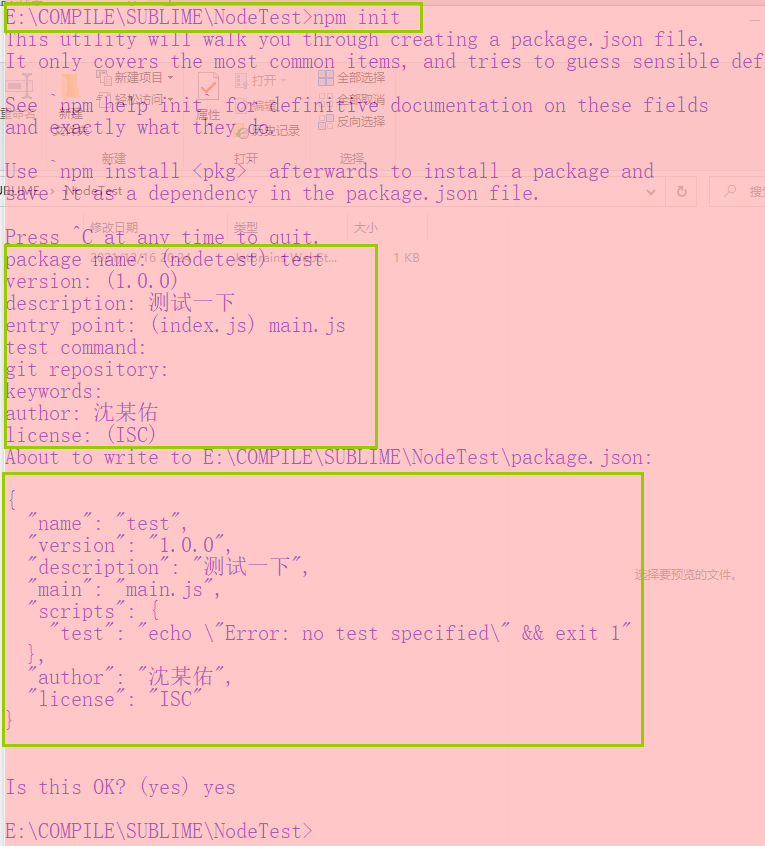
经过上述的一番操作之后,就会产生一个package.json文件,之后Node就会把当前文件夹视为一个包
下载包
其中的xxx是具体的包名
npm install xxx这里以math为例
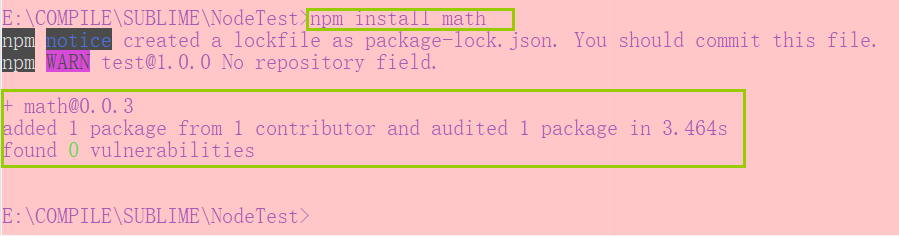
此后新增内容:
1.node_modules文件夹
其中包括了下载的包,比如这里下载的math。
2.package-lock.json
锁定安装时的版本号,并上传到git,保证其他用户在npm install下载的时候依赖保持一致。
package.json文件只能锁定大版本,也就是版本号的第一位,并不能锁定小版本,每次npm install就会拉取该大版本下最新的小版本。
package-lock.json则是在每次安装一个依赖的时候就锁定在安装这个版本。
使用包
在初始化的时候,我们设置了entry point为main.js,这就要求我们在根目录下新建一个main.js作为主函数(不知道该怎么称呼,暂时称为主函数好了)
// 因为是从NPM下载的,可以视为Node提供的,即核心模块,所以可以直接写名字引入
let math = require('math')
console.log('这是math:', math)
console.log('====================================')
console.log('调用math的add方法:', math.add(1,1))
console.log('====================================')
console.log('调用math的sum方法:', math.sum([1, 2, 3]))注意Node搜索包的过程是,首先搜索当前目录下的node_modules,在其中搜到了目标内容则直接使用;
否则进入上一级目录重复上述过程,递归直至搜索成功或搜索完根目录。
常用操作指令
| 指令 | 功能 |
|---|---|
| npm -v | 查看npm的版本 |
| npm version | 查看所有模块的版本 |
| npm search [包名] | 搜索包 |
| npm install [?包名] | 安装包,不加参数则安装所有依赖的包 如果在指令末尾加上–save 那么会把该包添加进package.json的依赖 如果在指令末尾加上 -g 那么会全局安装包(一般是全局安装工具) |
| npm remove [包名] | 删除包 |
| npm init | 初始化包 |
CNPM
NPM的服务器是在国外,下载速度有时比较慢。
CNPM则是在国内的镜像服务器,相对更稳定。
cnpm下载的内容不会覆盖npm下载的内容,其名称会有相应的标识。
Buffer缓冲区
简单使用
从结构上来看,Buffer和数组很像。但是相较于数组,Buffer性能更好,而且能够存储图片音频等二进制文件数据。
使用Buffer不需要引入模块,直接使用即可:
let str = 'Hello World'
let buf = Buffer.from(str)
console.log(buf)
数值对应的是unicode编码而不是ascii编码
存储的是二进制,但是打印出来的时候是十六进制,(因为二进制太长可读性太差),由于是两位数,所以取值范围是00-ff,即00-255,分别对应8位二进制0和1,即一个字节
缓冲区的长度计算
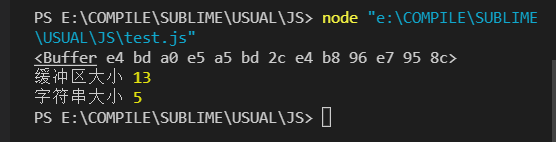
结合上面的内容,我们来分析下述代码:
let str = '你好,世界'
let buf = Buffer.from(str)
console.log('缓冲区大小',buf.length)
console.log('字符串大小',str.length)str的长度肯定是5,但是buf的长度又如何呢?
其中逗号采用的是英文逗号,而buf存储的又是字节,读入字符串时,默认采用UTF-8,而在UTF-8,汉字占3个字节,所以结果应该是4*3+1 = 13
当然,我们可以创建指定长度的buffer
// let buf2 = new Buffer(10) // 这种写法已经被删除
let buf3 = Buffer.alloc(10) // 推荐使用这种写法注意,Buffer的构造方法都已经废除了(就是别new了)
缓冲区的内容
let buf3 = Buffer.alloc(10) // 推荐使用这种写法
buf3[0] = 15
buf3[1] = 0x15
buf3[2] = 255, buf3[3] = 256, buf3[4] = 257
buf3[15] = 0x11
console.log(buf3)
console.log(buf3[15])
观察结果,我们可以发现
1.支持下标访问,自动转化为十六进制
2.静态且连续,不会动态扩容,越界非法访问无效
3.值会对最大值(255)进行取模运算(只保留二进制后八位)
并且在单独打印某个值时,它一定是十进制
buf3[1] = 0x15
console.log(buf3[1])输出结果是1 * 16 + 5,即 21
那么,要怎么指定进制输出呢?
(竟然是toString方法,完了忘完了)
console.log('这是十进制:', buf3[1])
console.log('这是二进制:', buf3[1].toString(2))
console.log('这是十六进制:', buf3[1].toString(16))输出结果分别是:21,10101,15
接下来,我们来看看Buffer的不安全分配:
let buf4 = Buffer.alloc(10)
let buf5 = Buffer.allocUnsafe(10)
console.log('安全分配:', buf4)
console.log('不安全分配:', buf5)输出结果是:
安全分配: <Buffer 00 00 00 00 00 00 00 00 00 00>
不安全分配: <Buffer 20 91 0b d1 46 02 00 00 60 92>
安全分配会将内容全部清空(归零)
不安全分配则会保留该部分内存的内容,省略一步操作其实性能还会好些(但是确实不安全啊)
其他操作
太多了懒得写,直接看官方文档
应用
服务器接收用户的二进制数据都先存到缓冲区等待处理
其余内容参见操作系统部分
FS文件模块
终于,要操作文件了
file system文件系统
所有操作都会有两种形式可供选择:同步和异步
之后的方法都会有两种形式:
一种名为xxxSync(同步),则一定有另一种名为xxx(异步)
同步写入
首先想一下文件写入的步骤:
1.打开文件
openSync(path,flags [, mode])
- path 文件路径
- flags 操作的类型: r读; w写;
- mode 可选参数,设置文件权限,一般不写
没有该文件则会创建该文件。
返回值是一个该文件的描述符,可以通过该描述符操作对应文件。通常是一个数字。
2.向文件中写入内容
writeSync(fd, string [,position [, encoding]])
- fd 文件描述符
- string 写入内容
- position 写入起始位置,一般不写
- encoding 编码格式,默认utf-8
3.保存并关闭文件
fs.closeSync(fd)
- fd 同上,文件描述符
let fd = fs.openSync('text.txt', 'w')
fs.writeSync(fd, '今天天气真不戳')
fs.writeSync(fd, '我要从第五十格开始写', 50)
// 其实是从五十一格开始写
fs.close(fd)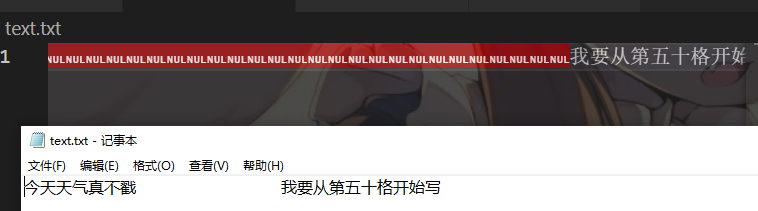
如果不指定位置,那么会直接清空原内容,写入新内容
当然有时候会发生两部分内容重叠导致的乱码…
异步写入
1.打开文件
open(path,flags [, mode],callback)
- path 文件路径
- flags 操作的类型: r读; w写;
- mode 可选参数,设置文件权限,一般不写
- callback 回调函数:两个参数,第一个为err(错误优先思想),没有错误则为null;第二个为fd,文件描述符,
没有该文件则会创建该文件。
没有返回值。
2.向文件中写入内容
writeSync(fd, string [,position [, encoding]])
- fd 文件描述符
- string 写入内容
- position 写入起始位置,一般不写
- encoding 编码格式,默认utf-8
3.保存并关闭文件
closeSync(fd)
- fd 同上,文件描述符
let fs = require('fs')
fs.open('text2.txt', 'w', (err, fd) => {
if (!err) {
fs.write(fd, '啊,这个兽偶好好看的哇~', (err) => {
if(!err) {
console.log('文件写入成功')
} else {
console.log('文件写入出错', err)
}
fs.close(fd, (err) => {
if(!err) {
console.log('文件关闭成功')
} else {
console.log('文件关闭出错', err)
}
})
})
} else {
console.log('文件打开出错', err)
}
})学到这里才意识到,一般而言异步函数是没有返回值的,多半是把结果放到参数里面来保存的
上面这个结构也让我更好的认识到了回调地狱
简单写入(异步封装)
fs.writeFile('text3.txt', '来啊放纵啊,反正有——大把时光~~', (err) => {
if(!err) {
console.log('成功写入,稳如老狗')
}
})这是一个对异步写入的封装
当然,简单文件写入方法还有其更多参数,比如可以传一个options对象,包括encoding编码格式,mode权限以及flag操作模式等等(可以通过修改flag为r来把方法变为读)
这个方法似乎没法指定从某一个位置开始写

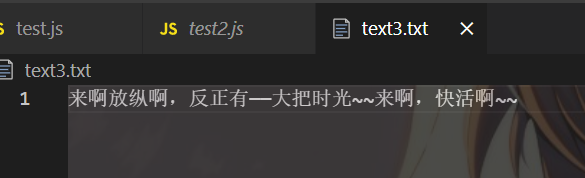
那如何追加而不是替换内容,我们参考上表,将flag操作模式的值设置为a再次尝试
fs.writeFile('text3.txt', '来啊,快活啊~~', {flag:'a'}, (err) => {
if(!err) {
console.log('成功写入,稳如老狗')
}
})
流式写入
同步、异步、简单写入都不适合大文件的写入,性能都比较差,容易导致内存溢出
流式写入则可以持续的、一部分一部分地写入文件
比喻就是,从水池A向水池B引水,流式输入就是两个水池间连接的管道——请记住这个比喻
最简单步骤是
1.创建一个可写流
createWriteStream(path [,options])
返回一个可写流对象
2.写入
write(string)
3.关闭可写流
close() 或者 end()
这里比喻一下:两个方法都是把管道拔掉,但是close是拔掉对面那头,end是拔掉我们这头。
区别在于,当我们把水都引入管道后,我们并不知道水是否已经进入对面的水池,拔掉对面那头的话可能导致还在管道中的水丢失;所以我们一般是先拔掉我们这边这头。
但是随着版本更迭,close可能出现的弊端似乎也得到了很好的修正(?管他的反正先end吧)
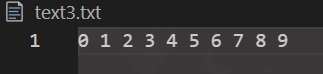
let fs = require('fs')
let ws = fs.createWriteStream('text3.txt')
console.log('这是可写流对象',ws)
for(let i = 0; i < 10; i ++)
ws.write(i + ' ')
ws.close()
默认的操作模式是w,也是对内容进行覆盖
我们还可有更多操作
监听
let fs = require('fs')
let ws = fs.createWriteStream('text3.txt', {flag:'a'})
ws.once('open', () => {
console.log('流打开了')
})
// console.log('这是可写流对象',ws)
for(let i = 0; i < 10; i ++)
ws.write(i + ' ')
ws.once('close', () => {
console.log('流关闭了')
})
ws.close()once和on一样,能够添加时间,但是once是只能触发一次的
简单读取(异步封装)
文件读取和写入也是一一对应的,也分为四种:同步 异步 简单 流式,前两种几乎和写入没有区别,所以不再赘述
流程也不再赘述,直接上代码
fs.readFile('text2.txt', (err, data) => {
//才想起来啊,throw直接抛出错误啊
if(err)
throw err
console.log('这是数据', data)
})输出结果如下
这是数据 <Buffer e5 a4 a9 e6 b0 94 e7 9c 9f e4 b8 8d e6 88 b3>
是十六进制的嘛,这咋看哦——这个时候就得归功于我们万能的toString了,原来它不只是能够转进制,还能直接给翻译回去,是真滴牛啤啊
let fs = require('fs')
fs.readFile('text2.txt', (err, data) => {
if(err)
throw err
console.log('这是数据:', ...data)
console.log('处理一手:', data.toString())
})而且我还发现,可以对buffer用展开运算符,展开之后直接变十进制,简直帅死了
输出结果如下:
这是数据: 229 164 169 230 176 148 231 156 159 228 184 141 230 136 179
处理一手: 天气真不戳
注意,这里可不只是能够读文本,还可以读图片等超文本
比如像下面这样
fs.readFile('pic.png', (err, data) => {
if(err)
throw err
let biPic = data
console.log(biPic)
fs.open('pic2.png', 'w', (err, fd) => {
if(err)
throw err
fs.write(fd, biPic, (err) => {
if(err)
throw err
fs.close(fd)
})
})
})
流式读取
大家或许会觉得依葫芦画瓢,写是怎么样读就怎么样,但是流式读取还真不是那样的——所以这里单独拎出来说一说
监听data事件
监听可读流访问数据
懒得多说了直接上代码
let rs = fs.createReadStream('video.mp4')
rs.once('open', () => {
console.log('开启流')
})
rs.on('data', (data) => {
console.log(data)
})
rs.once('close', () => {
console.log('关闭流')
})可读流似乎不用手动关闭,一旦读取完毕自动关闭
总之就是非常大的数据啦
结合可写流,我们能够实现视频的复制:
let fs = require('fs')
let rs = fs.createReadStream('video.mp4')
let ws = fs.createWriteStream('video2.mp4')
rs.once('open', () => {
console.log('可读流---开启')
})
rs.once('close', () => {
console.log('可读流---关闭')
// 可读流关闭,那么可写流也可以关闭了
ws.end()
})
ws.once('open', () => {
console.log('可写流---开启')
})
ws.once('close', () => {
console.log('可写流---关闭')
})
rs.on('data', (data) => {
console.log(data)
})
这样就实现了一个文件的复制
当然上述内容太麻烦了,这里还有一种更为简单的方法管道
管道的具体概念参见操作系统,使用方式如下:
rs.pipe(ws)这样就建立起了rs和ws之间的管道,将可读流的内容输出到可写流中,是对之前的代码的一次封装
其他操作
验证路径是否存在
fs.exists(path, callback) //已经废止,用fs.stat替代
fs.existsSync(path)获取文件信息
fs.stat(path, callback)
fs.statSync(path)删除文件
fs.unlink(path, callback)
fs.unlinkSync(path)当然还有更多方法,具体使用参阅官方文档
常用核心模块及其API
url模块
import url = require('url')url.parse()
第一个参数是url字符串,返回一个URL对象,具有protocol、hostname、query、path等属性
第二个参数如果为true,则会将query再解析为对象
url.format()
将URL对象转为URL字符串
url.resolve()
用于URL拼接,能够识别相对路径等
var a = url.resolve('/one/two/three', 'four')
var b = url.resolve('http://example.com/', '/one')
var c = url.resolve('http://example.com/one', '/two');
var d = url.resolve('http://example.com/one/ddd/ddd/ddd', './two');
var e = url.resolve('http://example.com/one/ddd/ddd/ddd', '../two');
var f = url.resolve('http://example.com/one/ddd/ddd/ddd', '.../two');
console.log(a +","+ b +","+ c+','+d+','+e+','+f);
//输出结果:
/one/two/four,
http://example.com/one,
http://example.com/two,
http://example.com/one/ddd/ddd/two,
http://example.com/one/ddd/two
http://example.com/one/ddd/ddd/.../two
querystring模块
querystring.escape()
编码,在接下来的stringify等方法中会自动调用这个方法
作用是将中文转化为编码字符
querystring.unescape()
解码,能够将编码的字符还原为原本的文字
querystring.parse()
反序列化,将query字符串转化为Query对象
querystring.stringify()
序列化,将Query对象转化为query字符串
querystring.stringify ({name:"a", age: 1}, ",", ":")第一个参数是操作的对象,
第二个参数是指定键值对间分隔方式,
第三个参数可省略,默认值为:,指定键值间分隔方式
第四个参数可省略,用于配置,详情查阅官方文档
结果
“name:a,age:1”
queryString常用于处理post请求,用于规范化(序列化)数据
所谓的序列化,就是处理成对象的形式
之所以要这样“多此一举”,是因为总有像Y70一样的大佬,用postman绕开前端的输入合法性检验,直接发送一些稀奇古怪的字符串过来——这导致JSON.parse()无法将其转换为对象,直接引发后端的崩溃
https模块
和http的方法基本上都一样
https爬虫
非常容易,代码如下
const https = require ('https')
const url = 'https://uland.taobao.com/sem/tbsearch'
https.get (url, (res) => {
let html = ''
res.on ('data', (chunk) => {
html += chunk
})
res.on ('end', () => {
console.log(html)
})
res.on ('err', (err) => {
console.log(err)
})
})cheerio
用于内容筛选,是第三方包,需要先npm安装
其语法类似JQ,筛选方式是用CSS选择器的形式筛选:
const cheerio = require ('cheerio')
function filter (html) {
const $ = cheerio.load (html)
const footer = $('#alimama-footer')
const text = []
// console.log(footer)
footer.each((index, value) => {
text.push ($(value).text())
})
return text
}
request
可以看做封装的AJAX,能发起请求,也能拿到响应
const https = require ('https')
const options = {
hostname: 'api.douban.com',
port: 443,
method: 'GET',
path: 'v2/movie/top250'
}
const request = https.request (options, (response) => {
console.log (response)
})
request.on ('error', (error) => {
console.error (error)
})
request.end()
当然也可以这样拿
const request = https.request (options, (response) => {
// console.log (response)
response.setEncoding('utf8')
// 不设置编码格式的话默认是buffer
// 设置为utf8之后返回的是JSON
response.on ('data', (chunk) => {
console.log(chunk)
})
response.on('end', () => {})
})如果我们要发起post请求,那么需要像下面这样
这是一个自动评论b站视频的脚本,这里由于个人隐私,部分数据以xxx代替
const https = require ('https')
const qs = require ('querystring')
const postData = qs.stringify({
'oid': 'xxx',
'type':'1',
'message':'发个评论测试一下',
'plat':' 1',
'ordering':'heat',
'jsonp':'jsonp',
'csrf':'xxx'
})
const options = {
hostname: 'api.bilibili.com',
port: '443',
method: 'POST',
path: '/x/v2/reply/add',
header: {
// xxx
}
}
const request = https.request (options, (response) => {
console.log ('请求结果', response.statusCode)
})
request.on ('error', (err) => {
console.error (err)
})
request.write (postData)
request.end ()事件模块
Events类
注意这个是一个类,所以我们继承一下方便扩展
const Events = require ('events')
class Player extends Events {}
const player = new Player ()emit()
player.on ('play', (title) => {
console.log(`正在播放:《${title}》`)
})
player.emit ('play', 'JAVA零基础到入坟')emit就是触发事件,第二个参数是作为事件的参数,可以考虑封装成对象然后传多个参数
这里用on的话,那么通过emit能够多次触发;
如果用once的话,那么就只能触发一次;
文件模块
也就是fs模块,我们在之前的FS文件模块章节已经说过了
这里再做一点补充,内容比较多,建议参考官方文档
| 关键词 | 名称 |
|---|---|
| stat | 得到文件与目录的信息 |
| mkdir | 创建一个目录 |
| writeFile appendFile |
创建文件并写入内容 |
| readFile | 读取文件的内容 |
| readdir | 列出目录的东西 |
| rename | 重命名目录 |
| rmdir unlink |
删除目录与文件 |
async模块
需要npm安装
串行无关联
串行和并行
大概可以这么理解,比如,并行是每次发送1B,串行则是把1B拍烂为8b发送,这样的好处是:
- 可以减少对带宽的占用量,减少成本——没错,理想情况下只占用原带宽的1/8,8b排成一个队列传输(这意味着一个队列中是同步的)
- 就算传输过程中丢包了,相较于一次损失1B而言,能够减少数据的损失量
先看一段普通的异步代码:
console.time('test1')
// 开始计时
setTimeout(() => {
console.log('test1-begin')
}, 2000)
setTimeout(() => {
console.log('test1-end')
console.timeEnd('test1')
// 结束计时, 结果约为4s
}, 4000)可以这么理解,setTimeout本身是同步的,其中的回调才是异步的
同步执行期间,将setTimeout定时任务放入异步任务队列,并开始计时,时间到后就触发,所以到4s的时候就触发了
知道了这点,那么下面这段代码的结果也不难推测了:
console.time('test1')
setTimeout(() => {
console.log('test1-begin')
}, 2000)
setTimeout(() => {
setTimeout(() => {
console.log('test1-end')
console.timeEnd('test1') // 10s
}, 6000)
}, 4000)那么,接下来看看串行无关联代码?
使用async.series()执行串行无关联代码,
第一个参数是数组,其内放置需要执行的任务
第二个参数则是回调,获取执行结果
const async = require('async')
console.time('test2')
async.series([
// 任务1
function (callback) {
setTimeout(() => {
// 执行后将'one'放到res中
callback(null, 'one')
}, 2000)
},
// 任务2
function (callback) {
setTimeout(() => {
// 执行后将'two'放到res中
callback(null, 'two')
}, 4000)
}
// 回调
], function (err, res) {
// ['one', 'two']
console.log(res)
// 约6s
console.timeEnd('test2')
})
可以看到,两个异步的方法似乎产生了某种同步执行,耗时是两者之和
并行无关联
并行,已经是猜到结果了,不过,这里并行N个任务,是否会z真的开启N条线程,或者是模拟N个线程?——这是个问题,有知道的大佬还请指点一下
const async = require('async')
console.time('test3')
async.parallel([
function (callback) {
setTimeout(() => {
callback(null, 'one')
}, 2000)
},
function (callback) {
setTimeout(() => {
callback(null, 'one')
}, 4000)
}
], function (err, res) {
console.log(res)
// 约6s
console.timeEnd('test3')
})诶嘿,好啊又回到了最初的起点了,4s
串行有关联
这个有关联说的是参数之间的传递,前面2个例子中,callback都会将内容传给最后的回调函数——这就是说数组中的几个方法之间无关联
而有关联则是,第一个方法callback将把数据传给下一个方法,这样一直到最后一个方法,最后一个方法的callback将把所有数据传给回调函数
console.time('test3')
async.waterfall([
function (callback) {
callback(null, 'one')
},
// data1即上一个方法的callback的one
function (data1, callback) {
callback(null, data1, 'three')
},
function (data1, data2, callback) {
callback(null, [data1, data2, 'three'])
}
], function (err, res) {
// [ 'one', 'three', 'three' ]
console.log(res)
console.timeEnd('test3')
})Net模块
Net模块主要是为了实现socket
Soket
网络上两个程序通过一个双向的通信连接实现数据的交换,连接的一端称为一个socket
建立socket服务端连接的流程一般是六步:
- 创建socket
- 将socket绑定某个端口
- 开始监听这个端口
(这之后可以开始接受其他socket的连接请求了)- 接受请求
- 从socket中读取字符
- 关闭(当然,可以不关闭,一直处于连接状态)
而建立客户端的流程则是:
- 创建socket
- 请求连接另一个socket
- 发送数据
- 关闭(当然,也可以不关闭)
之后写了一个 聊天服务端-客户端 的代码,后面放到Node后端开发那篇里面吧
WebSocket
WebSocket和Socket
这是一个需要着重注意的关键知识点Socket是TCP/IP的网络API——想想看,你的浏览器是怎么连上网的?浏览器是一个应用程序(应用层),它调用操作系统提供的
Socket来使用协议栈中TCP、UDP等传输层协议
(Socket是为了方便应用层操作传输层而抽象出来的一层,是一组API)这样一来,浏览器等应用程序才有了数据收发能力WebSocket是一个应用层协议——它是基于TCP的,是HTML5更新的内容之一,意义是以全双工的即时通讯替代了高频轮询。使用WebSocket而不是直接调用Socket的好处就是,能够更亲和web环境,可以把通信的UI由终端的小黑窗换到了浏览器窗口
另外,这里还有一个Socket.io可以了解一下。这是一个兼容方案,兼容那些不支持H5的浏览器。(当然,它是一个第三方包,使用的话记得先要手动npm一下)
但是现在都2022了,大部分情况可以不用在意这个东西了
后记
前方是星辰大海,寻找知识,让世界成为你的画布!



