前言
写在开篇
在这短短数十天的学习中,我的认知也有了长足的进步,不再把前端局限于web,因为我见识到了更为广大的前端,那是奇伟瑰丽的,也是人迹罕至的,当我见到这一幕时的心情,就像是远行者历经千辛万苦终于要翻过一个山头的时候怀揣的期待被山头那边高不可攀的“真正的顶峰”打破,随即而来的震撼
这次远足,没有终点
对于没有终点这种概念无需产生惶恐,心怀敬仰地用有限去博弈无穷,向世界献上赞歌,这何尝不是一种浪漫呢
更新日志
2022/02/03
开始学习吧2022/02/04
搜集各种资料,学习关于“信息熵”的知识并做好记录
浏览器原生多媒体和扩展
音频和视频
这里指的是audio标签和video标签
它们具有如下属性:
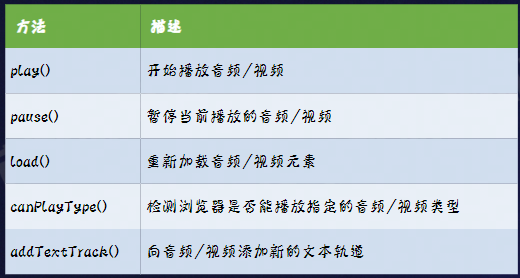
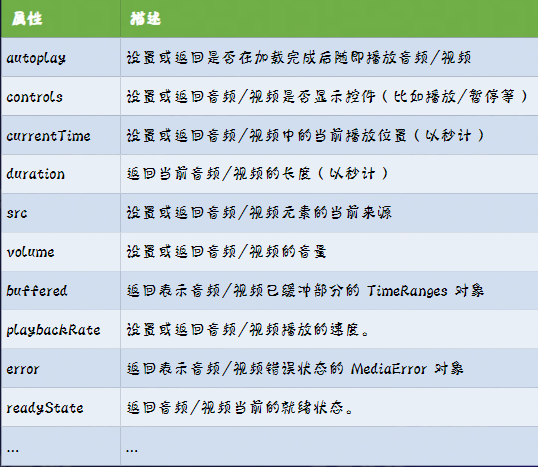
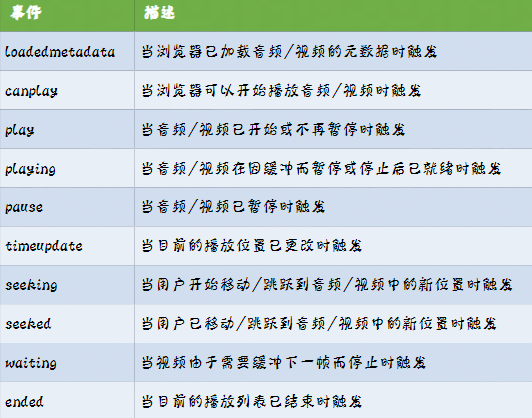
由于现在的浏览器很可能会避免随机噪声的出现,所以会禁用如autoplay这种属性,从而直接配置是无效的,所以我们需要使用JS来触发它们(我还没试过,可能也没效果)
缺陷
不支持直接播放hls、flv等格式的视频
视频资源的请求和加载无法通过代码控制
(无法实现分段加载、清晰度无缝切换、精准预加载等功能)
多媒体元素和扩展API
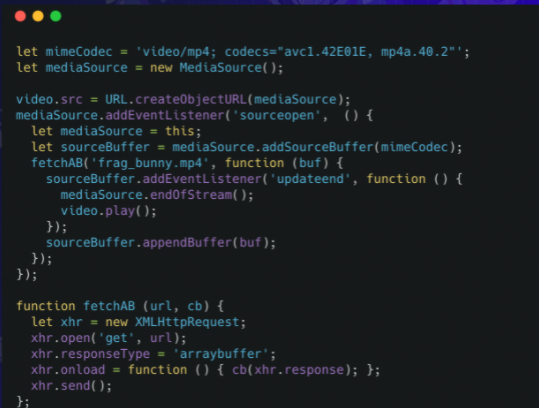
MSE使用过程:
- 创建mediaSource实例
- 创建指向mediaSource的URL
- 监听sourceopen事件
- 创建sourceBuffer
- 向sourceBuffer中加入数据
- 监听updateend事件
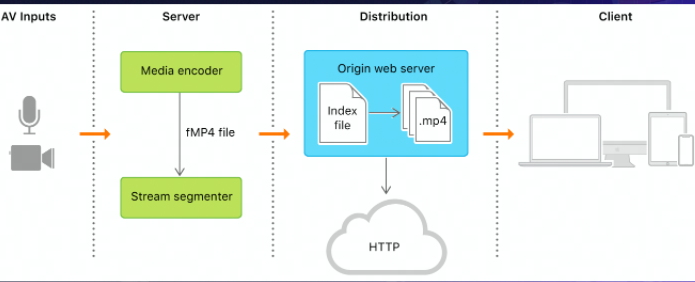
而用MSE播放mp4的过程如下:
对比一下播放器播放mp4:
- 数据加载(ts flv mp4)
- 解封装(音频裸流、视频裸流)
- 重封装(fmp4)
- appendBuffer(video、audio)
- 解码渲染(解码渲染)
- 音视频同步(时间戳)

流媒体协议
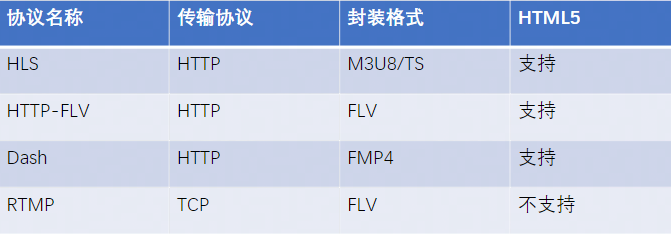
其中,HLS全称是HTTP Live Streaming,用于实时音视频流的传输,目前HLS协议被广泛应用于视频点播和直播领域
工作流程
Web多媒体基础知识
Web多媒体历史
多媒体历史可以大致的分为三个阶段:
- Flash时代
已经开摆了- HTML5时代
至今还在用,但是audio等标签完全不够用,亟待扩展- Media Source Extension(MSE)时代
媒体资源扩展,未来的发展趋势
图像的基本概念
图像分辨率
用于确定组成一副图像的像素数据
就是指在 水平和垂直方向上图像所具有的像素个数
图像深度
图像深度是指存储每个像素所需要的比特数
图像深度决定了图像的每个像素可能的颜色数,或可能的灰度级数
例如:
彩色图像每个像素用R,G,B三个分量表示,每个分量用8位,像素深度为24位,可以表示的颜色数目为2的24次方,既16777216个
单色图像存储每个像素需要8bit,则图像的象素深度为8位,最大灰度数目为2的8次方,既256个。
视频基本概念
分辨率
指的是构成视频的每一帧图像的分辨率
帧率
视频单位时间内包含的视频帧的数量
码率
视频单位时间内传输的数据量,一般用kbps表示——注意这里是bit不是Byte
编码格式
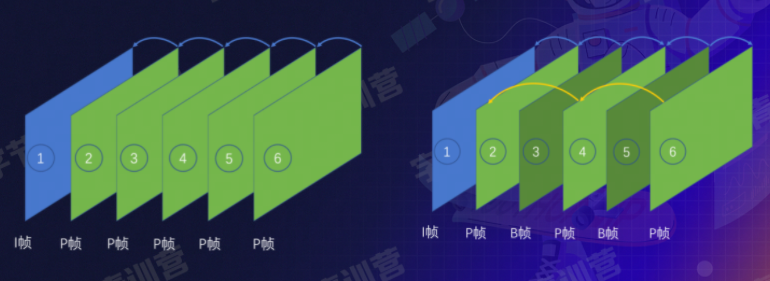
I帧
又称帧内编码帧,是一种自带全部信息的独立帧,无需参考其他图像便可独立进行解码
P帧
又称帧间预测编码帧,需要参考前面的I帧或者P帧才能进行编码
B帧
又称双向预测编码帧,也就是B帧记录的是本帧与前后帧的差别
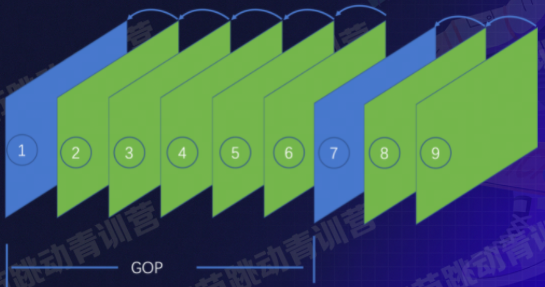
GOP
group of picture
指的是两个I帧之间的间隔
下面这些是常见的编码格式:
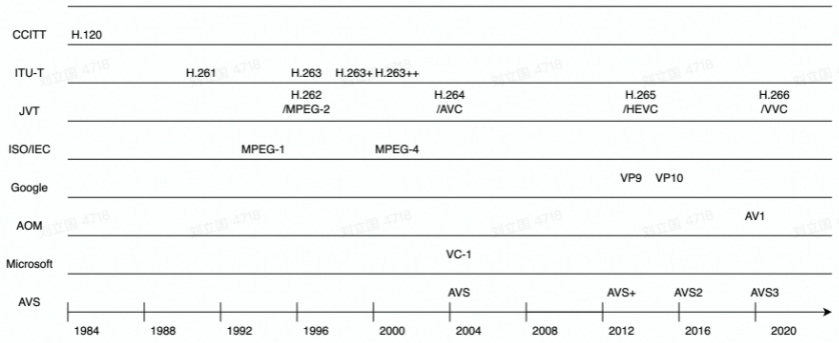
为什么要进行编码
编码是将源对象内容按照一种标准转换为一种标准格式内容
解码是和编码对应的,它使用和编码相同的标准将编码内容还原
最初是为了加密,经过加密的内容不知道编码标准的人很难识别
而现在主要是为了信息交换
编码可以做到压缩体积等效果,有效优化一些冗余问题
冗余
从信息论的角度来看,描述信息源的数据是信息和数据冗余之和,即:数据=信息+数据冗余。
空间冗余
又称几何冗余
同一景物表面上采样点的颜色之间通常存在着空间关联性,相邻各点的取值往往近似或者相同,这就是空间冗余
例如图片中有一片连续的区域像素都是相同的颜色,那么空间冗余就产生了
图像数据中经常存在的一种数据冗余,是静态图像中存在的最主要的一种数据冗余

图中虚线划出的区域便是
时间冗余
又称帧间冗余
在视频、动画图像中,相邻帧之间往往存在着时间和空间的相关性
例如人们在会议室中开会,随着会议的进行,时间在改变,但是背景(房间、家具等)一直是相同的、而且没有移动,变化的只是人们的动作和位置
这里的背景就反映为时间冗余。同样,由于人在说话时产生的音频也是连续和渐变的,因此声音信息中也会存在时间冗余

视觉冗余
又称心理视觉冗余
在多媒体技术的应用领域中,人的眼睛是图像信息的接收端。视觉冗余是相对于人眼的视觉特性而言的,人类的视觉系统并不能对图像画面的任何变化都能感觉到,通常情况下具有以下特点:
- 对亮度的变化敏感,对色度的变化相对不敏感
- 对静止图像敏感,对运动图像相对不敏感
- 对图像的水平线条和竖直线条敏感,对斜线相对不敏感
- 对整体结构敏感,对内部细节相对不敏感
- 对低频信号敏感,对高频信号相对不敏感(如:对边沿或者突变附近的细节不敏感)
- …..
因此,包含在色度信号、运动图像、图像高频信号中的一些数据,相对于人眼而言,并不能对增加图像的清晰度作出贡献,被人眼视为多余的,这就是视觉冗余。

编码冗余
推测可能是指的信息熵冗余
具体的例子可以参考哈夫曼编码解决的问题:如何用0 1两种字符代表26个字母——哈夫曼编码能在这个问题中得到最优解,解决的正是编码冗余问题(但是哈夫曼编码在特定的情况下无法得到最优解)
数据压缩的理论极限是信息熵原理:
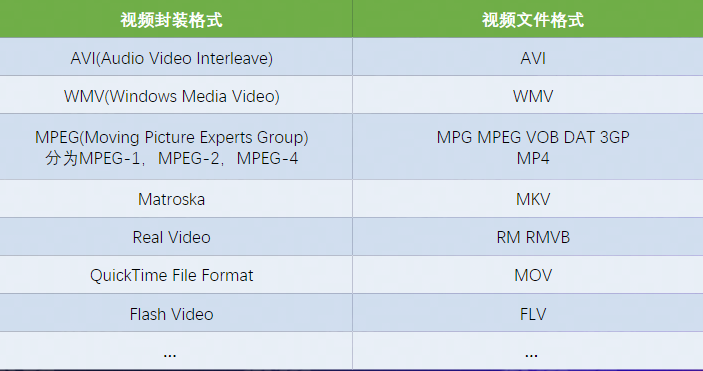
信息论之父香农指出,任何信息都存在冗余,冗余大小与信息中每个符号(数字、字母或单词)的出现概率或者说不确定性有关。香农借鉴了热力学的概念,把信息中排除了冗余后的平均信息量称为“信息熵”,并给出了计算信息熵的数学表达式:
其中,pi代表随机事件i出现概率,log通常是以2为底——这里对数的底数选择是任意的,因为信息熵其实是一个相对值,但是传统是以2为底,这样一来不仅可以使得数据有通用性,而且还能用bit作为单位
如果要求编码过程中不丢失信息量,即要求保存信息熵,这种信息保持编码叫熵编码,是无损压缩的
常用的熵编码:
香农编码、 哈夫曼编码、 算术编码、 BLE行程编码、CAVLC基于上下文的自适应变长编码、CABAC基于上下文的自适应二进制算术编码
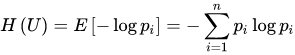
更多的冗余
还有其他多种冗余形式,比如结构冗余、其他冗余等等..
此处不再一一例举
编码处理过程
基本顺序依次为:
- 预测
减少空间冗余、时间冗余- 变换
减少空间冗余- 量化
减少视觉冗余- 熵编码
去除编码冗余
封装格式
封装格式是存储音视频、图片或者字幕信息的一种容器
总结
又一次感受到数学对计算机的印象,多亏了本次学习探索,窥见图像处理这个领域的一隅。
同时也勾起了对WebGPU,WebVR,WebXR,Webassembly,WebCodecs的向往
期待这些技术成熟时为我们带来的惊艳!
参考文献
字节跳动青训营培训资料
百度百科
https://baike.baidu.com/item/%E7%A9%BA%E9%97%B4%E5%86%97%E4%BD%99
https://baike.baidu.com/item/%E6%97%B6%E9%97%B4%E5%86%97%E4%BD%99
https://baike.baidu.com/item/%E8%A7%86%E8%A7%89%E5%86%97%E4%BD%99
https://baike.baidu.com/item/%E7%86%B5%E7%BC%96%E7%A0%81《图像处理学习笔记》
https://blog.csdn.net/qq_33208851/article/details/95335809《走进Web多媒体技术》
https://juejin.cn/post/7000726903787094029



